
Elasticsearch 相关度评分
Elasticsearch 查询时会有一个默认的排序,这个默认排序的依据就是 相关度评分(_score) 。
相关度评分背后的理论
相关度评分计算相关的理论知识见 官方文档,简单来说有以下几个关键字:
词频(term frequency)(TF)
词在 文档 中出现的频度是多少? 频度 越高,权重 越高。
逆向文档频率(inverse document frequency)(IDF)
词在 集合所有文档 里出现的频率是多少?频次 越高,权重 越低。
字段长度归一值(norm)
字段的长度是多少? 字段 越短,字段的权重 越高。
向量空间模型(vector space model)
这个比较难理解,下面是摘自 官方文档 中的说明:
向量空间模型 提供一种比较 多词查询 的方式,单个评分代表文档与查询的匹配程度,为了做到这点,这个模型将文档和查询都以 向量(vectors)的形式表示:
向量实际上就是包含多个数的一维数组,例如:
javascript[1,2,5,22,3,8]在向量空间模型里,向量空间模型里的每个数字都代表一个词的 权重 ,与 词频/逆向文档频率(term frequency/inverse document frequency) 计算方式类似。
查询时权重提升
也就是查询时通过指定 查询条件的 boost 参数来影响相关度评分。boost 参数默认值为 1。
下面的示例说明 title 字段的权重较高。
GET /_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": {
"query": "quick brown fox",
"boost": 2
}
}
},
{
"match": {
"content": "quick brown fox"
}
}
]
}
}
}另外还可以通过 indices_boost 参数来提升索引的权重。
下面的示例是查询所有 docs_2014_ 前缀的索引,其中 docs_2014_10 和 docs_2014_09 的权重较高。
GET /docs_2014_*/_search
{
"indices_boost": {
"docs_2014_10": 3,
"docs_2014_09": 2
},
"query": {
"match": {
"text": "quick brown fox"
}
}
}使用查询结构修改相关度
通过修改查询的结构来调整查询的优先级。
GET /_search
{
"query": {
"bool": {
"should": [
{ "term": { "text": "quick" }},
{ "term": { "text": "brown" }},
{ "term": { "text": "red" }},
{ "term": { "text": "fox" }}
]
}
}
}将 brown 和 red 当做同义词,修改后查询结构如下:
GET /_search
{
"query": {
"bool": {
"should": [
{ "term": { "text": "quick" }},
{ "term": { "text": "fox" }},
{
"bool": {
"should": [
{ "term": { "text": "brown" }},
{ "term": { "text": "red" }}
]
}
}
]
}
}
}Not Quite Not
使用 boosting 查询实现满足指定条件的 文档降级显示。
满足 positive 条件的文档会被查询出来,其中满足 negative 条件的文档会被降级显示(= _score * negative_boost)。
GET /_search
{
"query": {
"boosting": {
"positive": {
"match": {
"text": "apple"
}
},
"negative": {
"match": {
"text": "pie tart fruit crumble tree"
}
},
"negative_boost": 0.5
}
}
}忽略 TF/IDF
有时仅需要查询一个词在字段中是否出现过,不需要关心 TF/IDF。
这时可以使用 constant_score 查询,可以指定查询或过滤,为文档指定评分为 1,忽略 TF/IDF 信息。
另外还可以通过 boost 参数提升查询的权重。
GET /_search
{
"query": {
"bool": {
"should": [
{ "constant_score": {
"query": { "match": { "description": "wifi" }}
}},
{ "constant_score": {
"query": { "match": { "description": "garden" }}
}},
{ "constant_score": {
"boost": 2
"query": { "match": { "description": "pool" }}
}}
]
}
}
}function_score 查询
这个功能很强大,可以改变甚至完全替换原始查询评分。
Elasticsearch 预定义了一些函数:
weight
为每个文档应用一个简单而不被规范化的权重提升值:当 weight 为 2 时,最终结果为
2 * _score。field_value_factor
使用这个值来修改 _score ,如将 popularity 或 votes (受欢迎或赞)作为考虑因素。
random_score
为每个用户都使用一个不同的随机评分对结果排序,但对某一具体用户来说,看到的顺序始终是一致的。(一致随机)
衰减函数 —— linear 、 exp 、 gauss
将浮动值结合到评分 _score 中,例如结合 publish_date 获得最近发布的文档,结合 geo_location 获得更接近某个具体经纬度(lat/lon)地点的文档,结合 price 获得更接近某个特定价格的文档。
script_score
如果需求超出以上范围时,用自定义脚本可以完全控制评分计算,实现所需逻辑。
按受欢迎度提升权重
结合 function_score 查询 与 field_value_factor 查询可以实现按照文档的字段来影响文档评分。
GET /blogposts/post/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes"
}
}
}
}上面查询结果文档的最终评分:
new_score = old_score * number_of_votes
这样会导致 votes 为 0 的文档评分为 0,而且 votes 值过大会掩盖掉全文评分。
modifier
一般会使用 modifier 参数来平滑 votes 的值。
GET /blogposts/post/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log1p"
}
}
}
}应用值为 log1p 的 modifier 后的评分计算公式:
new_score = old_score * log(1 + number_of_votes)
modifier 的可以为:
- none (默认状态)
- log
- log1p
- log2p
- ln
- ln1p
- ln2p
- square
- sqrt
- reciprocal
factor
可以通过将 votes 字段与 factor 的积来调节受欢迎程度效果的高低:
GET /blogposts/post/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log1p",
"factor": 2
}
}
}
}添加了 factor 会使公式变成这样:
new_score = old_score * log(1 + factor * number_of_votes)
boost_mode
或许将全文评分与 field_value_factor 函数值乘积的效果仍然可能太大,我们可以通过参数 boost_mode 来控制函数与查询评分 _score 合并后的结果,参数接受的值为:
multiply
评分 _score 与函数值的积(默认)
sum
评分 _score 与函数值的和
min
评分 _score 与函数值间的较小值
max
评分 _score 与函数值间的较大值
replace
函数值替代评分 _score
与使用乘积的方式相比,使用评分 _score 与函数值求和的方式可以弱化最终效果,特别是使用一个较小 factor 因子时:
GET /blogposts/post/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log1p",
"factor": 0.1
},
"boost_mode": "sum"
}
}
}之前请求的公式现在变成下面这样:
new_score = old_score + log(1 + 0.1 * number_of_votes)
max_boost
最后,可以使用 max_boost 参数限制一个函数的最大效果:
GET /blogposts/post/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log1p",
"factor": 0.1
},
"boost_mode": "sum",
"max_boost": 1.5
}
}
}无论 field_value_factor 函数的结果如何,最终结果都不会大于 1.5 。
注意 max_boost 只对函数的结果进行限制,不会对最终评分 _score 产生直接影响。
过滤集提升权重
使用 function_score 查询的 weight 函数。
GET /_search
{
"query": {
"function_score": {
"filter": {
"term": { "city": "Barcelona" }
},
"functions": [
{
"filter": { "term": { "features": "wifi" }},
"weight": 1
},
{
"filter": { "term": { "features": "garden" }},
"weight": 1
},
{
"filter": { "term": { "features": "pool" }},
"weight": 2
}
],
"score_mode": "sum",
}
}
}过滤 vs. 查询
首先要注意的是 filter 过滤器代替了 query 查询,在本例中,我们无须使用全文搜索,只想找到 city 字段中包含 Barcelona 的所有文档,逻辑用过滤比用查询表达更清晰。
过滤器返回的所有文档的评分 _score 的值为 1。
function_score 查询接受 query 或 filter ,如果没有特别指定,则默认使用 match_all 查询。
函数 functions
functions 关键字保持着一个将要被使用的函数列表。
可以为列表里的每个函数都指定一个 filter 过滤器,在这种情况下,函数只会被应用到那些与过滤器匹配的文档。
例子中,我们为与过滤器匹配的文档指定权重值 weight 为 1(为与 pool 匹配的文档指定权重值为 2)。
评分模式 score_mode
每个函数返回一个结果,所以需要一种将多个结果缩减到单个值的方式,然后才能将其与原始评分 _score 合并。
评分模式 score_mode 参数正好扮演这样的角色,它接受以下值:
- multiply :函数结果求积(默认)。
- sum :函数结果求和。
- avg :函数结果的平均值。
- max :函数结果的最大值。
- min :函数结果的最小值。
- first :使用首个函数(可以有过滤器,也可能没有)的结果作为最终结果
在本例中,我们将每个过滤器匹配结果的权重 weight 求和,并将其作为最终评分结果,所以会使用 sum 评分模式。
不与任何过滤器匹配的文档会保有其原始评分, _score 值的为 1。
随机评分
在评分相同的结果时很有用。可以提高相同评分结果的展现率,使其有相似的几率展现出来。
让每个用户看到不同的随机次序,但同一用户查询结果的相对次序能始终保持一致。
这种行为被称为 一致随机(consistently random) 。
使用 random_score 函数及其 seed 参数可以实现查询结果的一致随机。
random_score 函数会输出一个 0 到 1 之间的数, 当种子 seed 值相同时,生成的随机结果是一致的,例如,将用户的 会话 ID 作为 seed :
GET /_search
{
"query": {
"function_score": {
"filter": {
"term": { "city": "Barcelona" }
},
"functions": [
{
"filter": { "term": { "features": "wifi" }},
"weight": 1
},
{
"filter": { "term": { "features": "garden" }},
"weight": 1
},
{
"filter": { "term": { "features": "pool" }},
"weight": 2
},
{
"random_score": {
"seed": "the users session id"
}
}
],
"score_mode": "sum"
}
}
}越近越好
根据距离、价格等排序时很有用。比如查询距离当前位置较近的门店、当前产品价格差不多的产品等。
这需要使用 function_score 查询提供的一组 衰减函数(decay functions)
linear 线性函数
exp 指数函数
gauss 高斯函数
所有三个函数都接受如下参数:
origin
中心点 或字段可能的最佳值,落在原点 origin 上的文档评分 _score 为满分 1.0 。
scale
衰减率,即一个文档从原点 origin 下落时,评分 _score 改变的速度。(例如,每 £10 欧元或每 100 米)。
decay
从原点 origin 衰减到 scale 所得的评分 _score ,默认值为 0.5 。
offset
以原点 origin 为中心点,为其设置一个非零的偏移量 offset 覆盖一个范围,而不只是单个原点。在范围 -offset <= origin <= +offset 内的所有评分 _score 都是 1.0 。
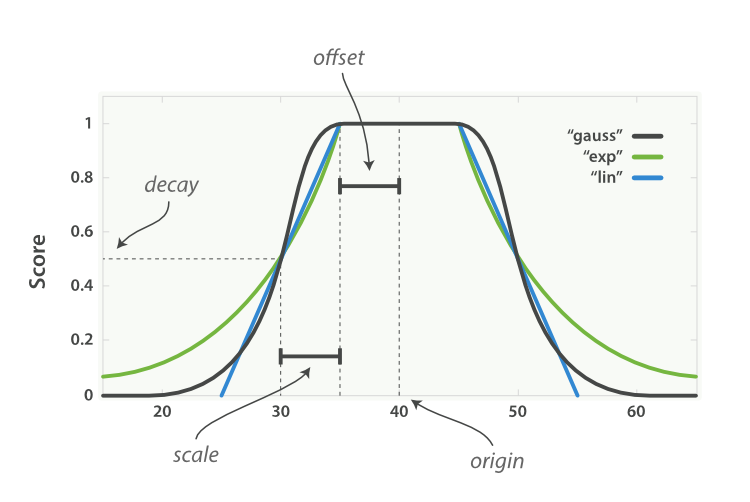
(图片摘自官方文档)
简单来说就是:
以 origin 为中心的距离为 0 到 offset 的范围内的评分为满分 1.0;
以 origin 为中心的距离为 offset 到 offset + scale 的范围内,评分为 decay (默认为 0.5);
三种曲线的区别:
linear 线性函数是条直线,一旦直线与横轴 0 相交,所有其他值的评分都是 0.0。
exp 指数函数是先剧烈衰减然后变缓。
gauss 高斯函数是钟形的——它的衰减速率是先缓慢,然后变快,最后又放缓。
脚本评分
如果所有 function_score 内置的函数都无法满足应用场景,可以使用 script_score 函数自行实现逻辑。
Elasticsearch 里使用 Groovy 作为默认的脚本语言。
Groovy 示例:
price = doc['price'].value
margin = doc['margin'].value
if (price < threshold) {
return price * margin / target
}
return price * (1 - discount) * margin / targetscript_score 函数示例:
GET /_search
{
"function_score": {
"functions": [
{ ...location clause... },
{ ...price clause... },
{
"script_score": {
"params": {
"threshold": 80,
"discount": 0.1,
"target": 10
},
"script": "price = doc['price'].value; margin = doc['margin'].value;
if (price < threshold) { return price * margin / target };
return price * (1 - discount) * margin / target;"
}
}
]
}
}另外还支持 原生 Java 脚本 。
调试相关度是最后 10% 要做的事情
最相关 这个概念是一个难以触及的模糊目标。
如何监控和评价相关度的调整:监控测量搜索结果。
- 用户点击最顶端结果的频次,这可以是前 10 个文档,也可以是第一页的;
- 用户不查看首次搜索的结果而直接执行第二次查询的频次;
- 用户来回点击并查看搜索结果的频次;
- 等等诸如此类的信息。
本文主要整理自 官方文档 - 控制相关度,详细的还请看原文。
(※需要注意的是这个文档是基于 2.x 版本的,有些具体的计算公式和计算评分的方法已经不一样了。)